Aural Cascading Style Sheets (ACSS) are designed to separate presentation rules from content: as their name implies, they are the aural analogue to CSS. Given structured content (that is presentation independent) and a set of presentation rules (that are modality specific), producing visible or audible output requires formatting the content according to the specified presentation rules. In visual formatting (typesetting), the result of this process is a visual display list typically encoded as Postscript, PDF or some other set of page marking operators. In fact the visual side of the WWW is currently in the process of standardizing on an XML dialect for encoding such visual display lists: see the work on Scalable Vector Graphics (SVG).
SABLE can be rightly viewed as an aural display list. That is in the overall architecture, SABLE is to auditory displays, what SVG is to visual displays. Notice that both these display list forms exhibit the desired characteristics of scaling, etc., that are not present in the result of playing such display lists -- such as GIF or JPEG in the visual context, or WAV files in the auditory context. Given the above analogy, it is self-evident that we need SABLE in order to capture and communicate aural display lists. The alternative in the absence of SABLE would be for audio formatters to directly make calls into a vendor-specific speech API to produce the spoken output, something that is clearly undesirable.
HTML documents may be rendered in a variety of media, including auditorily. When rendering a document auditorily one can specify how the rendering is to be done using Aural Cascaded Style Sheets. Thus one might wish to indicate that H1 elements are rendered using a particular voice. As an example of an Aural style specification, consider Figure 1, from Appendix A of the CSS2 Specification.
The sample specification in Figure 1 includes, for instance:
SABLE is being developed because there is an ever increasing demand for speech synthesis (TTS) technology in various applications including e-mail reading, information access over the web, tutorial and language-teaching applications, and in assistive technology for users with various handicaps. Due to incompatibilities in control sequences for various TTS systems, an application that was developed with a particular TTS system A cannot be ported, without a fair amount of additional work, to a new TTS system B, for the simple reason that the tag set used to control system A is completely different from those used to control system B. The large variety of tagsets used by TTS systems are thus a problem for the expanded use of this technology since developers are often unwilling to expend effort porting their applications to a new TTS system, even if the new system in question is of demonstrably higher quality than the one they are currently using. SABLE attempts to address this problem by proposing a standard markup scheme intended to be synthesizer independent.
More specifically, SABLE is being developed with the following goals in mind:
SABLE is based in part on two previous proposals:
SABLE, like its predecessors, supports two kinds of markup: the first - termed text description in STML, and structural elements in JSML - marks properties of the text structure that are relevant for rendering a document in speech. In the current version of SABLE, text description is handled by the DIV tag, whose attribute TYPE may be set to such values as sentence, paragraph or even stanza; and by SAYAS, which marks the function of the contained region (e.g. as a date, an e-mail address, a mathematical expression, etc.), and thereby gives hints on how to pronounce the contained region. The second kind of markup - STML's speaker directives or JSML's production elements - control various aspects of how the speech is to be produced. Falling into this latter category are tags such as: EMPH (marks levels of emphasis); PITCH (sets intonational properties); RATE (sets speech rate); and PRON (provides pronunciations as phonemic strings).
In both its generality and its coverage, SABLE has many advantages over existing markups such as Microsoft's SAPI, or Apple's Speech Manager control set:
<SABLE> Welcome to the demonstration of the Sable markup language using the Bell Labs TTS system. <SPEAKER gender=female age=younger> This system allows you to play around with a subset of the functionality of Sable. For example, you can switch languages between </SPEAKER> <LANGUAGE ID=FRA> fran�ais </LANGUAGE> <LANGUAGE ID=ESL-MEXICAN> espa�ol </LANGUAGE> <LANGUAGE ID=ESL-CASTILIAN> espa�ol </LANGUAGE> <LANGUAGE ID=ITA> italiano </LANGUAGE> <LANGUAGE ID=RON> <SPEAKER AGE=middle GENDER=female></SPEAKER> </LANGUAGE> <LANGUAGE ID=DEU> Deutsch </LANGUAGE> <LANGUAGE ID=ZHO CODE=BIG5>
</LANGUAGE> You can also <EMPH LEVEL=2.0> emphasize </EMPH> words, or put a break <BREAK LEVEL=large MSEC=200 TYPE="?"> between them. <PITCH RANGE=HIGHEST> You can set properties of the pitch range, <RATE SPEED=fastest> or the speech rate </RATE> . </PITCH> As we saw above, <SPEAKER age=child> you can set the speaker </SPEAKER> . You can insert an audio file, in this case an example of our Russian TTS system: <AUDIO SRC=http://www.bell-labs.com/project/tts/russian6.wav> And you can override the text by a call to the engine tag: <ENGINE ID=BLTTS DATA="This is the Bell Labs TTS System."> You won"t hear this. </ENGINE> You can set the <PRON SUB="pronounciation"> pronunciation </PRON> of a word, though we do not currently support IPA. Finally you can control aspects of how some kinds of strings are said using the &Quot;say as&Quot; tag. For example, a date in English: <SAYAS MODE=date MODETYPE=dmy> 18/11/1960 </SAYAS> or in French: <LANGUAGE ID=fra> <SAYAS MODE=date MODETYPE=dmy> 18.11.1960 </SAYAS> </LANGUAGE> Just be careful to keep some whitespace between tags and surrounding material. The parser is not very smart. See the file Read me dot text for further information. </SABLE>
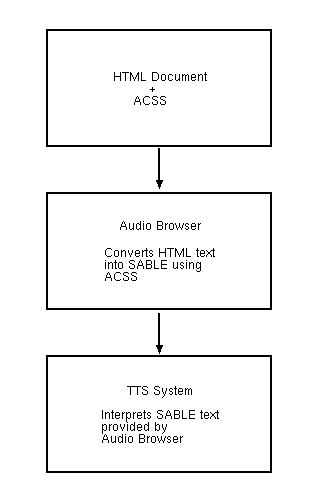
The answer is straightforward: ACSS should be used to provide aural
stylesheets; the ACSS specifications should be implemented by a voice
browser in a synthesizer-independent fashion using SABLE; this text
would then be read to users using their favorite TTS system. The
architecture would be thus as in Figure
3.
Figure 3: A Model for Using ACSS and SABLE. Note that the "HTML
Document" specified in the top box could well be any XML document.
Audio Formatters
The model of the relation between ACSS and SABLE discussed in the
preceding section and diagrammed in Figure
3 presumes the existence of automatic audio formatters that
consume XML content and ACSS style sheets to produce a SABLE stream
suitable for sending to a TTS-engine. It is our intention that such
tools will be provided in the future for at least that subset of ACSS
that is practically implementable in current TTS systems.
The model of the interaction would be as follows. Consider the implementation of an H1 tag using the ACSS from Figure 1. Say the audio browser encounters the text
<H1> Introduction </H1>in an HTML document using this ACSS. The specifications for all tags of the header (H) family are that it is "male" and that its stress is "20". . For H1, the pitch is "x-low" and the pitch-range is "90" (relatively high). Putting this all together, we have a male voice, speaking in the low part of its range, with a high pitch range, and lower than normal ("20") stress. Note that the "90" (also the "20") are on a 0-100 scale, where "50" is considered "normal". Thus "90" could be interpreted as 80% above the normal. In SABLE terms this might translate into:
<PITCH BASE=lowest RANGE=80%> <EMPH LEVEL=0.5> Introduction </EMPH> </PITCH>Note that we translate stress=20 using the EMPH tag, with a low setting for the pitch-level attribute; the single tag PITCH implements the two properties pitch=x-low (BASE=lowest) and pitch-range=90 (RANGE=80% or in other words 80% above the current setting in place, assuming the current is the normal range). So the audio browser should produce use the ACSS specification to convert the H1 element into the equivalent SABLE elements shown above.
In a similar vein, some of the SABLE tags, which have heretofore seemed useful in the design of SABLE purely as a markup language for TTS, may need to be reconsidered in the context of the WWW. For instance, SABLE provides a SAYAS tag, which is used to specify various modes of rendering specific stretches of text: for instance one can specify that a string "2/3" is to be read as a date in the "day-month" format. One problem with this approach is that the set of such potential markup seems open-ended: it may be desirable to also add such things as "speak as an age", "speak as a sports score", and so forth. Whether this kind of knowledge should be handled in the interface between SABLE and TTS, or in the interface between ACSS and SABLE is a question that needs to be thrashed out.